Le Yang (杨乐)
Special Research Fellow (特聘研究员)
Xi'an Jiaotong University
Google Scholar 中文主页🧑🎓 Bio
I'm currently as a special research fellow at Xi'an Jiaotong University and as a member of the AI-SEC research Lab in Xi'an Jiaotong University led by Chinese Academy of Science (CAS, 中国科学院院士) Fellow, Xiaohong Guan (管晓宏) and IEEE Fellow Prof. Chao Shen (沈超). My research mainly focuses on AI security and computer vision, in particular Trustworthy AI, Large Vision-Language Models(LVLMs), Dynamic Neural Networks, Efficient Learning/Inference, and Video Understanding.
🔥Our group is looking for self-motivated Ph.D/Master candidates and undergraduate student interns for ongoing research. Please drop me an email with your resume if you are interested.
🏫 Work Experience
- 05/2025 - now, Special Research Fellow, Xi'an Jiaotong University.
- 06/2021 - 05/2025, Assistant Professor, Xi'an Jiaotong University.
- 06/2021 - 05/2025, Postdoctoral researcher, Xi'an Jiaotong University. Advised by CAS Fellow, Prof. Xiaohong Guan.
- 12/2021 - 07/2022, Visiting Scholar, ML Group, Aalto University. Cooperating with Academy of Finland Research Fellow, Dr. Arno Solin.
📚 Education
- 09/2015 - 06/2021, Ph.D., Department of Automation, Tsinghua University. Advised by Prof. Shiji Song and Prof. Gao Huang.
- 09/2011 - 07/2015, B.E., Department of Automation, Northwestern Polytechnical University.

📰News
- 01/2026: 🎉 Our work, DeepEyes is accepted by ICLR 202!
- 08/2025: 🏆 The paper we presented, LVLM-FDA, was awarded for being the Best Student Paper by KSEM 2025 (CCF-C)!
- 05/2025: 🔥 We release the code of our recent work, DeepEyes, which achieves the ability of thinking with images like Open-AI o3 model. [Project Page]
- 03/2025: 🎉 Our work, Nullu is accepted by CVPR 2025!
- 11/2024: 📑 We proposed a new efficient alignment method, Nullu to mitigate Object Hallucination issues in LVLMs.
- 08/2024: 🎉 Our work, OstrDARTS is accepted by T-CYB!
- 07/2024: 🎉 Our work, EfficientGEBD is accepted by ACM MM 2024!
- 07/2024: 🎉 Three of our works (DyFADet, DyBDet, and Typographic-attack-for-LVLM) are accepted by ECCV 2024!
- 06/2023: 🎉 Our work, CoViFocus is accepted by T-CSVT!
📄 Publications
Representative Publications
Full publication list

DeepEyes: Incentivizing “Thinking with Images” via Reinforcement Learning [PDF] [Project Page] [code] [News]
Ziwei Zheng*, Michael Yang*, Jack Hong*, Chenxiao Zhao*, Guohai Xu✉, Le Yang✉, Chao Shen, XingYu
International Conference on Learning Representations (ICLR), 2026
In this paper, we try to build an LVLM with "thinking with images" like Open-AI o3 model. We explore the interleaved multimodal reasoning paradigm and introduce DeepEyes. The "thinking with images" capabilities are incentivized through end-to-end reinforcement learning without the need for cold-start SFT. Notably, this ability emerges natively within the model itself, leveraging its inherent grounding ability as a tool instead of depending on separate specialized models. Specifically, we propose a tool-use-oriented data selection mechanism and a reward strategy to encourage successful tool-assisted reasoning trajectories.DeepEyes achieves significant performance gains on fine-grained perception and reasoning benchmarks and also demonstrates improvement in grounding, hallucination, and mathematical reasoning tasks. Interestingly, we observe the distinct evolution of tool-calling behavior from initial exploration to efficient and accurate exploitation, and diverse thinking patterns that closely mirror human visual reasoning processes.

Nullu: Mitigating Object Hallucinations in Large Vision-Language Models via HalluSpace Projection [PDF] [code]
Le Yang*, Ziwei Zheng*, Boxun Chen, Zhengyu Zhao, Chenhao Lin, Chao Shen✉.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
The paper proposes Nullu, a method to reduce object hallucinations (OH) in LVLMs by projecting input features into the Null space of an unsafe subspace called HalluSpace. HalluSpace is identified by isolating hallucinated features and removing truthful ones. By suppressing LLM priors causing OH, Nullu enhances contextual accuracy without extra inference cost, showing strong performance across LVLM families.
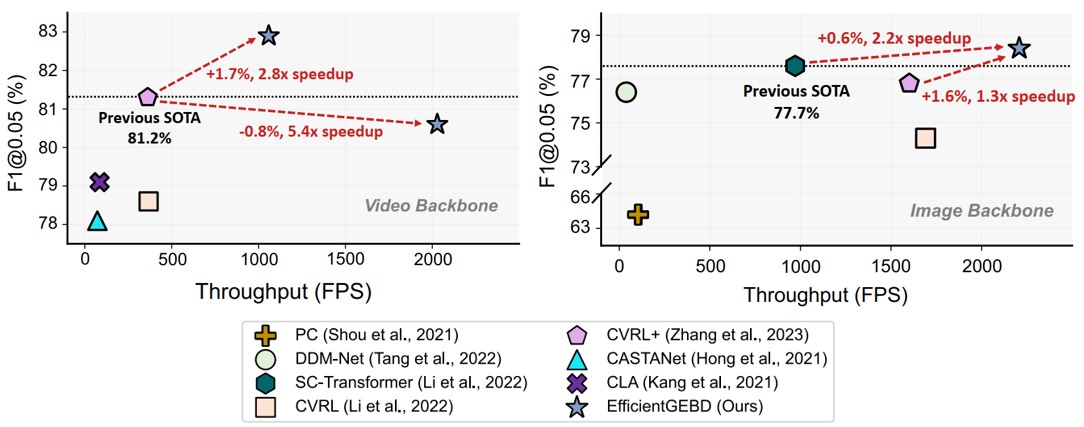
Rethinking the Architecture Design for Efficient Generic Event Boundary Detection
[PDF]
[code]
Ziwei Zheng, Zechuan Zhang, Yulin Wang, Shiji Song, Gao Huang, Le Yang✉.
ACM Multimedia (ACM MM), 2024
In this paper, we experimentally reexamine the architecture of GEBD models and uncover several surprising findings, demonstrating that some of sophisticated designs are unnecessary for building GEBD models. We also show that the GEBD models using image-domain backbones conducting the spatiotemporal learning in a spatial-then-temporal greedy manner can suffer from a distraction issue, which might be the inefficient villain for the GEBD.
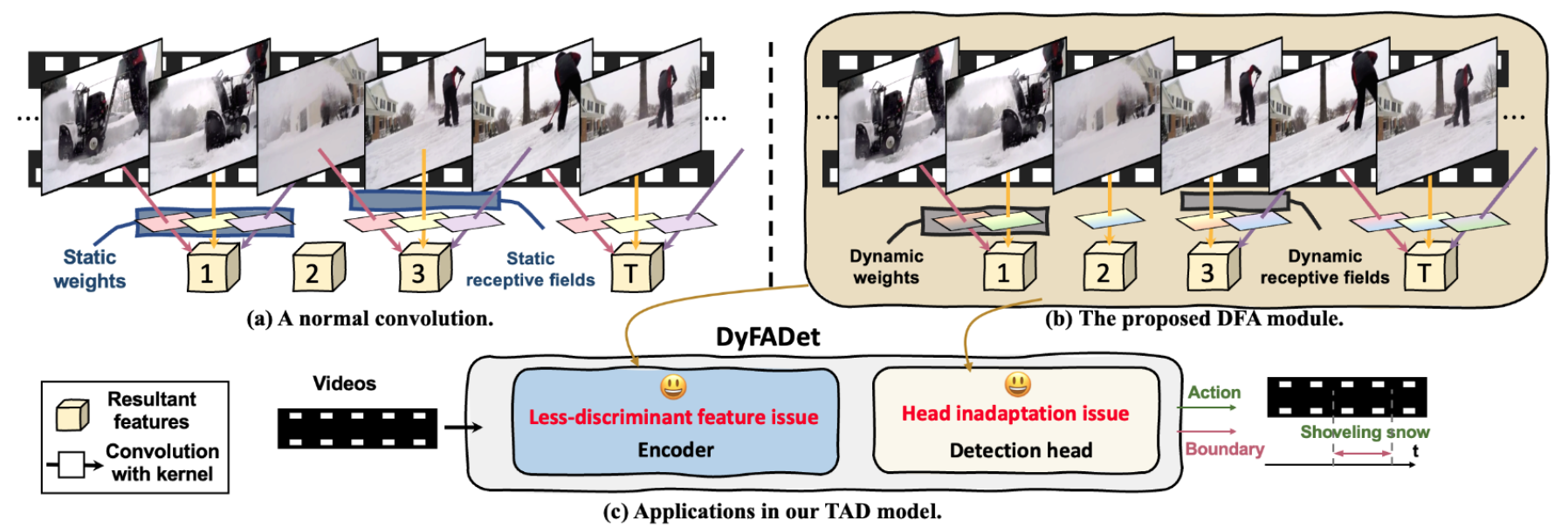
DyFADet: Dynamic Feature Aggregation for Temporal Action Detection [PDF] [code]
Le Yang*✉, Ziwei Zheng*, Yizeng Han, Hao Cheng, Shiji Song, Gao Huang, Fan Li.
European Conference on Computer Vision (ECCV), 2024
Inspired by the successes in dynamic neural networks, in this paper, we build a novel dynamic feature aggregation (DFA) module that can simultaneously adapt kernel weights and receptive fields at different timestamps. Based on DFA, the proposed dynamic encoder layer aggregates the temporal features within the action time ranges and guarantees the discriminability of the extracted representations. Moreover, using DFA helps to develop a Dynamic TAD head (DyHead), which adaptively aggregates the multiscale features with adjusted parameters and learned receptive fields better to detect the action instances with diverse ranges from videos.

Dynamic Spatial Focus for Efficient Compressed Video Action Recognition [PDF]
Ziwei Zheng, Le Yang✉, Yulin Wang, Miao Zhang, Lijun He, Gao Huang, Fan Li.
IEEE Transactions on Circuits and Systems for Video Technology (T-CSVT), 2023
We propose the fist dynamic spatial focus video recognition model for compressed video (such as MPEG4 and HEVC).
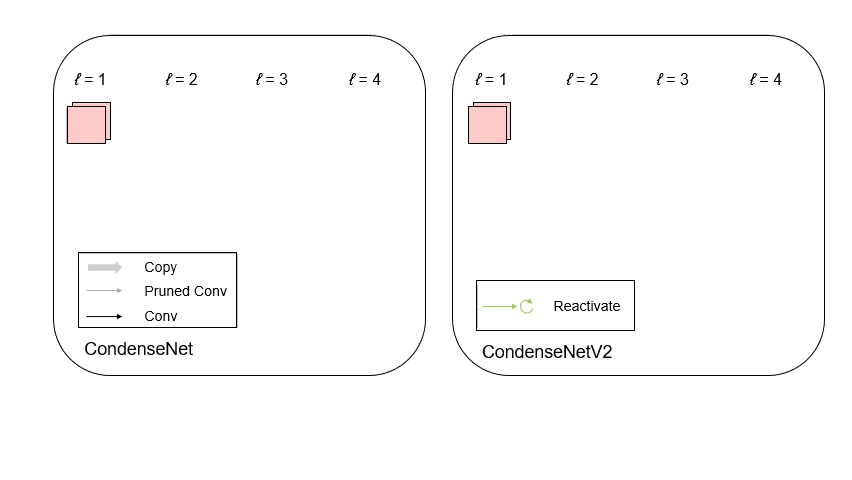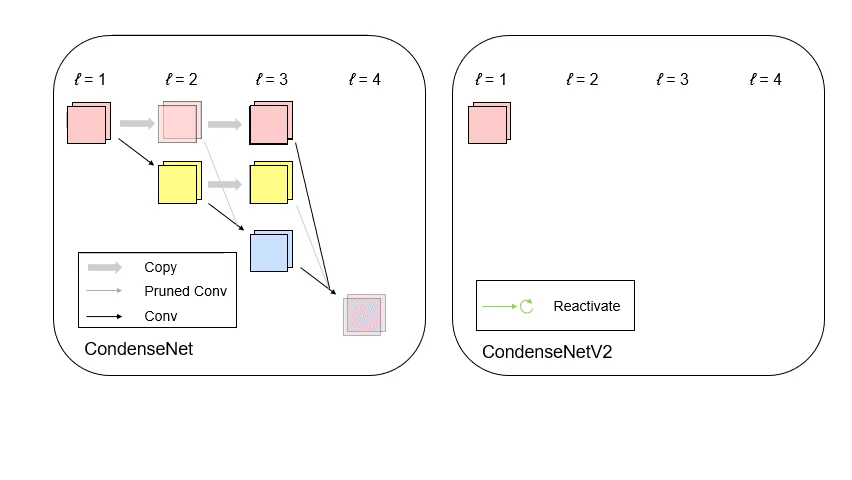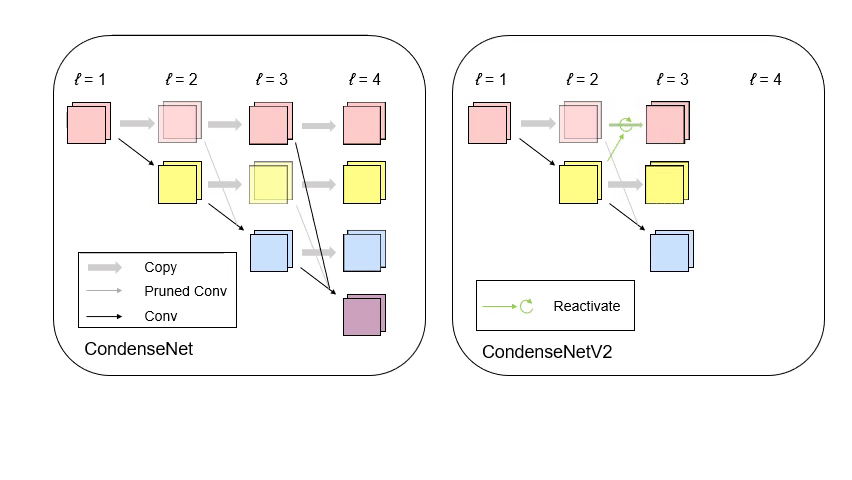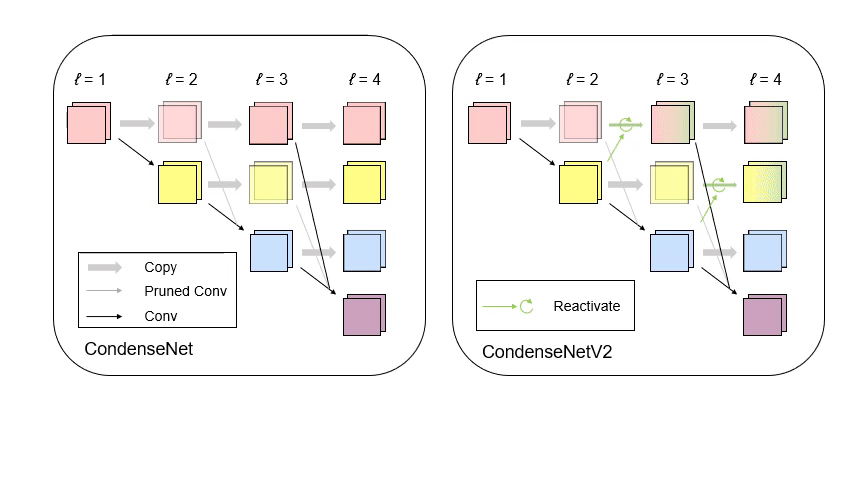
CondenseNet V2: Sparse Feature Reactivation for Deep Networks [PDF][code][知乎]
Le Yang*, Haojun Jiang*, Ruojin Cai, Yulin Wang, Shiji Song, Gao Huang✉, Qi Tian.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
We propose a new feature reusing method in deep networks through dense connectivity, which can simultaneously learn to 1) selectively reuse a set of most important features from preceding layers; and 2) actively update a set of preceding features to increase their utility for later layers.
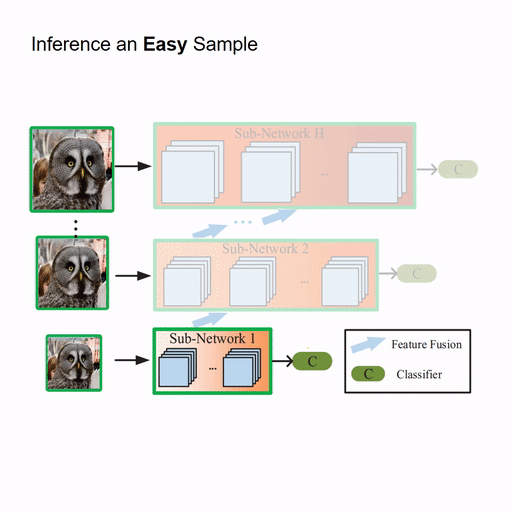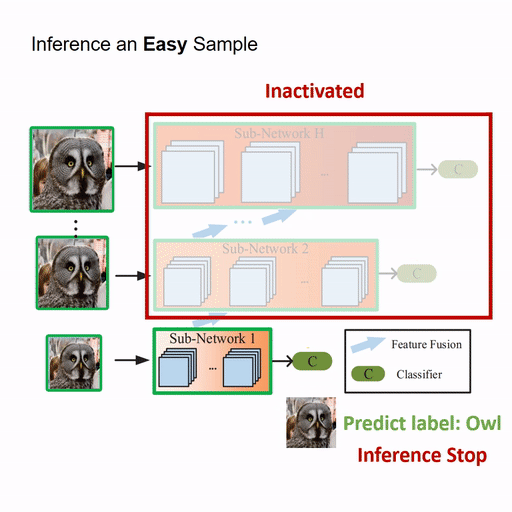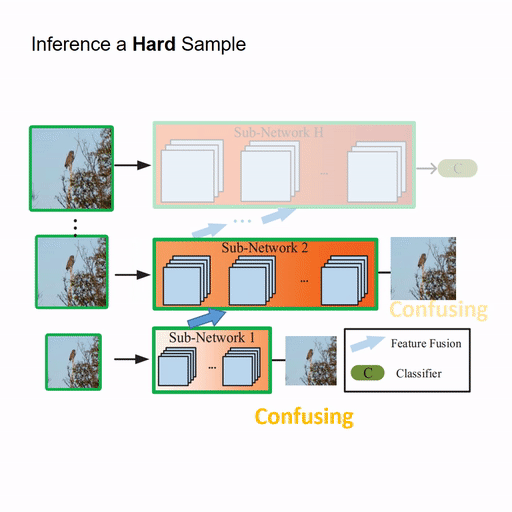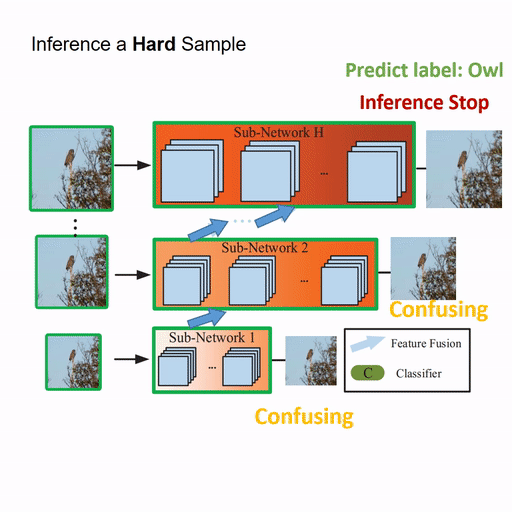
Resolution Adaptive Networks for Efficient Inference [PDF] [code]
Le Yang*, Yizeng Han*, Xi Chen*, Shiji Song, Jifeng Dai, Gao Huang✉
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
The proposed Resolution Adaptive Network (RANet) makes use of spatial redundancy in images to conduct the adaptive inference for the first time. The RANet is inspired by the intuition that low-resolution representations are sufficient for classifying “easy” inputs containing large objects with prototypical features, while only some “hard” samples need spatially detailed information.
🎖 Awards
- The First Prize of Natural Science Award, CSIG(2024 CSIG 自然科学一等奖), 2024.
- The 2021 Postdoctoral Innovative Talent Program(2021博新计划), advised by CAS Fellow, Prof. Xiaohong Guan, 2021.
- Outstanding Graduate of Tsinghua University (清华大学优秀毕业生), 2021.
- Outstanding Graduate of Beijing (北京市优秀毕业生), 2021.
🧑💻 Professional Activities
- Area Chair of ICPR 2026.
- Technical Programm Committee of UbiComp2023-CPD, MobiCom2024-PICASSO.
- Program Committee (PC) member of IJCAI 2021, AAAI 2026, ...
- Reviewer for IJCV, T-PAMI, T-NNLS, T-Cyber, T-CSVT, ...
- Reviewer for CVPR, ICCV, IJCAI, NeurIPS, ICML, ICLR...
📧 Contact
- yangle15 at xjtu dot edu dot cn
- Address: Room 140, Pengkang building, Xingqing Campus, Xi'an Jiaotong University, Xi'an 710049, China.